
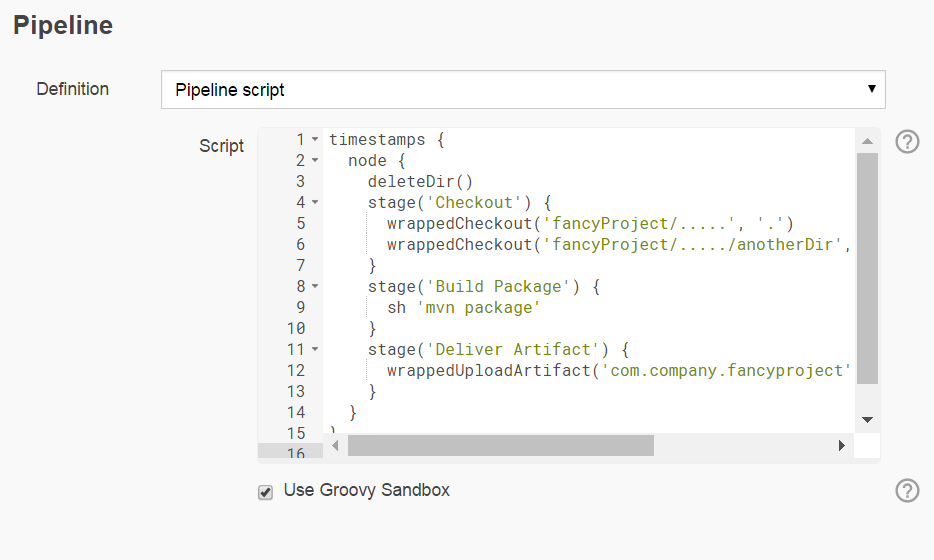
In der Praxis sehe ich viele Pipelines mit Jenkins, die nach folgender Praxis erstellt wurden: Man möchte X tun, schlägt in Beispielen nach oder in der Pipeline Steps Reference. Der entsprechende Pipeline Step, modifiziert um die eigenen Parameter landet schließlich im Jenkinsfile. Man möchte Y tun, findet wiederum den richtig parametrierten Step und trägt ihn unter Y in das Jenkinsfile.
Zum Beispiel vielleicht etwa so: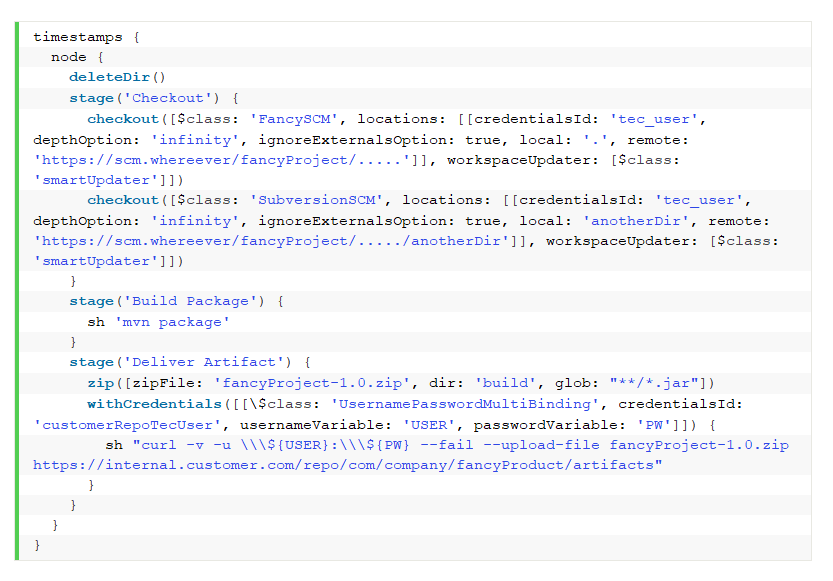
Das Refactoring wird durch das Pipeline-Gestrüpp, das auf dem/den Build-Server(n) entstehen wird, schließlich auch nicht einfacher: Wo optimiert werden kann/muss, wo (wenn überhaupt) noch nach alten Vorgaben gearbeitet wurde, ist schwer auszumachen. Und die Angst, dass Änderungen unvorhersehbare, schwer zu entdeckende Folgen und Seiteneffekte haben, ist mehr als verständlich.
Bei der Erstellung und Pflege der Pipelines mit Jenkins in unterschiedlichen Projekten und Unternehmen macht man oft diese Beobachtungen:
- Es wird nur ein einziger SCM-Server mit einer einzigen Technologie verwendet.
- Für die CI wird meist der gleiche User verwendet bzw. wurde eigens dafür eingerichtet.
- Für alle Projekte wird nur ein Artefakt-Repositorium für die Uploads verwendet.
- Es gibt es Schritte, die jedem Projekt helfen würden, wenn man sie leicht verfügbar zur Hand hat.
Daraus lassen sich Best-Practices bezüglich der Anwendung der Pipeline-Steps entwickeln:
- Der checkout-Step kann sehr übersichtlich gekapselt werden.
- Für den Artefakt-Upload-Step ist dies ebenfalls möglich, egal ob dieser durch Maven/Gradle/Ivy/curl/… gemacht wird.
- Gleiches gilt für das Herunterladen von Artefakten, die für das Deployment benötigt werden.
- Hilfsschritte wie den Aufruf eines Config-Management-Systems und das Aufräumen des Workspace nach erledigtem bzw. gescheitertem Deployment können einfach zentral gehalten werden.
Konkrete Beispiele:
wrappedCheckout(relativeURL, localDir, user = ‚jenkins‘)
wrappedUploadArtifact(package, repo = ‚snapshot‘, artifactDir = ‚standardDir‘)
wrappedGetArtifact(package, repo = ‚snapshot‘, artifactDir = ‚standardDir‘)
wrappedCheckout(relativeURL, localDir, user = ‚jenkins‘)
wrappedUploadArtifact(package, repo = ‚snapshot‘, artifactDir = ‚standardDir‘)
wrappedGetArtifact(package, repo = ‚snapshot‘, artifactDir = ‚standardDir‘)
Die Verzeichnisse, aus denen die Artefakte genommen bzw. in das sie abgelegt werden kann vereinheitlich werden (convention over configuration).
Das Befüllen der Konfigurationsdateien, die für Deployment/Provisionierung benötigt werden:
wrappedCMS(package, projectName, version)
Hier können z. B. sensible Daten nach dem Deployment automatisch aufgeräumt werden:
wrappedCleanup()
Der eigentliche Pipeline-Code kann damit auf wenige kurze Zeilen reduziert werden. Eine Ausnahme bildet der eigentliche Build-Step. Oft zeigt sich, dass es bei den Parametern und bei den Build-Werkzeugen und deren Anwendung von Projekt zu Projekt Unteschiede gibt, oft bei gleicher Technologie. Dies erschwert ein effektives Wrapping in der vorgestellten Art.
Wenn wir die Wrappers verwenden und uns an die Konventionen halten, sieht die Pipeline am Anfang dann z. B. so aus: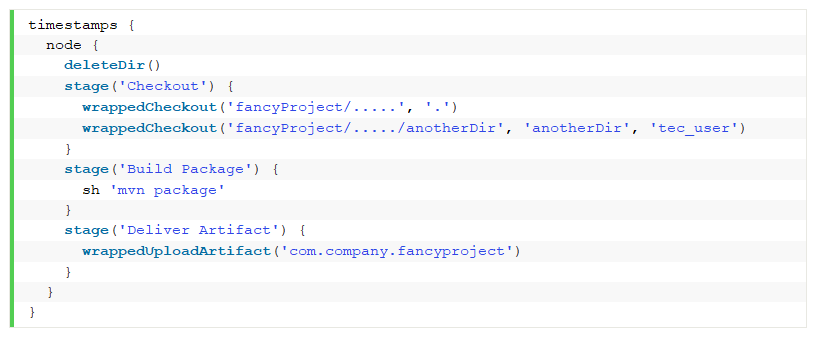
Der gemeinsam verwendete Code wird am besten im gleichen SCM-System an einem speziellen Ort gepflegt. Dieser kann in die Pipeline entweder durch einen eigenen Checkout, gefolgt von einem load() gebracht werden, oder man nutzt dafür die integrierte Skript-Bibliothek-Funktionalität des Jenkins. Ich werde darauf in einem späteren Beitrag eingehen.
